




















































![[Rumor] Trailer Marvel’s Wolverine Terbaru akan Hadir di State of Play Mendatang](https://gamebrott.com/wp-content/uploads/2025/09/Trailer-Terbaru-Marvels-Wolverine-Diperkiran-Hadir-Pada-State-of-Play-750x375.webp)














Model AI Claude 4 baru menyusun ulang kode selama 7 jam nonstop

Pada hari Kamis, Anthropic merilis Claude Opus 4 dan Claude Sonnet 4, menandai kembalinya perusahaan tersebut ke peluncuran model yang lebih besar setelah sebelumnya berfokus pada varian Sonnet kelas menengah sejak bulan Juni tahun lalu. Model-model baru tersebut merupakan apa yang disebut perusahaan sebagai model pengkodean yang paling mumpuni, dengan Opus 4 yang dirancang untuk tugas-tugas yang kompleks dan berlangsung lama yang dapat beroperasi secara mandiri selama berjam-jam.
Alex Albert, kepala Claude Relations di Anthropic, mengatakan kepada Ars Technica bahwa perusahaan tersebut memilih untuk menghidupkan kembali lini Opus karena permintaan yang terus meningkat untuk aplikasi AI yang bersifat agen. "Di semua perusahaan yang membangun berbagai hal, ada gelombang besar aplikasi agen yang bermunculan, dan permintaan serta premi yang sangat tinggi diberikan pada kecerdasan buatan," kata Albert. "Saya pikir Opus akan sangat cocok dengan alur tersebut."
Sebelum kita melangkah lebih jauh, penyegaran singkat mengenai tiga nama "ukuran" model AI Claude ( diperkenalkan pada Maret 2024) mungkin diperlukan. Haiku, Sonnet, dan Opus menawarkan keseimbangan antara harga (dalam API), kecepatan, dan kemampuan.
Model Haiku adalah yang terkecil, paling murah untuk dijalankan, dan paling tidak mampu dalam hal apa yang Anda sebut "kedalaman konteks" (mempertimbangkan hubungan konseptual dalam prompt) dan pengetahuan yang dikodekan. Karena ukuran kecil dalam hitungan parameter, model Haiku mempertahankan lebih sedikit fakta konkret dan dengan demikian cenderung lebih sering berkonspirasi (menjawab pertanyaan secara masuk akal berdasarkan kurangnya data) daripada model yang lebih besar, tetapi mereka jauh lebih cepat pada tugas-tugas dasar daripada model yang lebih besar. Sonnet secara tradisional merupakan model kelas menengah yang mencapai keseimbangan antara biaya dan kemampuan, dan model Opus selalu menjadi yang terbesar dan paling lambat untuk dijalankan. Namun, model Opus memproses konteks lebih dalam dan secara hipotetis lebih cocok untuk menjalankan tugas-tugas logis yang mendalam.
Belum ada Claude 4 Haiku, tetapi model Sonnet dan Opus yang baru kabarnya dapat menangani tugas-tugas yang tidak dapat dilakukan oleh versi sebelumnya. Dalam wawancara kami dengan Albert, ia menggambarkan skenario pengujian di mana Opus 4 bekerja secara koheren hingga 24 jam pada tugas-tugas seperti bermain Pokémon sambil mengode tugas-tugas refaktor dalam Claude Code yang berjalan selama tujuh jam tanpa gangguan. Model-model Claude sebelumnya biasanya hanya bertahan satu hingga dua jam sebelum kehilangan koherensi, kata Albert, yang berarti bahwa model-model tersebut hanya dapat menghasilkan keluaran yang merujuk pada dirinya sendiri selama itu sebelum mulai menghasilkan terlalu banyak kesalahan.
Secara khusus, klaim refaktor maraton itu dilaporkan berasal dari Rakuten , konglomerat layanan teknologi Jepang yang "memvalidasi kemampuan [Claude] dengan refaktor sumber terbuka yang menuntut yang berjalan secara independen selama 7 jam dengan kinerja berkelanjutan," kata Anthropic dalam rilis berita.
Apakah Anda ingin membiarkan model AI tanpa pengawasan selama itu adalah pertanyaan lain sepenuhnya karena bahkan model AI yang paling mampu pun dapat memperkenalkan bug yang halus, jatuh ke lubang kelinci yang tidak produktif, atau membuat pilihan yang tampak logis bagi model tetapi kehilangan konteks penting yang akan ditangkap oleh pengembang manusia. Sementara banyak orang sekarang menggunakan Claude untuk pengkodean getaran yang mudah, seperti yang telah kami bahas pada bulan Maret , "debugging getaran" yang diberdayakan manusia (dan ironisnya dinamai demikian) yang sering kali dihasilkan dari sesi pengkodean AI yang panjang juga merupakan hal yang sangat nyata. Selengkapnya tentang itu di bawah.
Untuk mengatasi beberapa kekurangan tersebut, Anthropic membangun kemampuan memori ke dalam kedua model Claude 4 yang baru, yang memungkinkan mereka untuk menyimpan berkas eksternal guna menyimpan informasi penting selama sesi yang panjang. Ketika pengembang menyediakan akses ke berkas lokal, model dapat membuat dan memperbarui "berkas memori" untuk melacak kemajuan dan hal-hal yang mereka anggap penting dari waktu ke waktu. Albert membandingkan hal ini dengan cara manusia membuat catatan selama sesi kerja yang panjang.
Pemikiran yang diperluas bertemu dengan penggunaan alat
Kedua model Claude 4 memperkenalkan apa yang disebut Anthropic sebagai "pemikiran yang diperluas dengan penggunaan alat," fitur beta baru yang memungkinkan model untuk bergantian antara penalaran simulasi dan penggunaan alat eksternal seperti pencarian web, mirip dengan apa yang saat ini dilakukan oleh model AI mini-high OpenAI o3 dan 04 di ChatGPT. Sementara Claude 3.7 Sonnet sudah memiliki kemampuan penggunaan alat yang kuat, model baru sekarang dapat menyisipkan penalaran simulasi dan pemanggilan alat dalam satu respons.
"Jadi sekarang kita benar-benar dapat berpikir, memanggil proses alat, hasilnya, berpikir lebih lanjut, memanggil alat lain, dan mengulanginya hingga mencapai jawaban akhir," Albert menjelaskan kepada Ars. Model-model tersebut menentukan sendiri kapan mereka telah mencapai kesimpulan yang berguna, suatu kemampuan yang diperoleh melalui pelatihan alih-alih diatur oleh pemrograman manusia yang eksplisit.
Dalam praktiknya, kami secara anekdot menemukan kemampuan penggunaan alat paralel sangat berguna dalam asisten AI seperti OpenAI o3, karena mereka tidak harus bergantung pada apa yang dilatih dalam jaringan saraf mereka untuk memberikan jawaban yang akurat. Sebaliknya, model yang lebih agen ini dapat menelusuri web secara berulang, mengurai hasil, menganalisis gambar, dan menjalankan tugas pengodean untuk analisis dengan cara yang dapat menghindari jatuh ke dalam perangkap konfabulasi dengan hanya mengandalkan keluaran LLM murni.
“Model pengkodean terbaik di dunia”
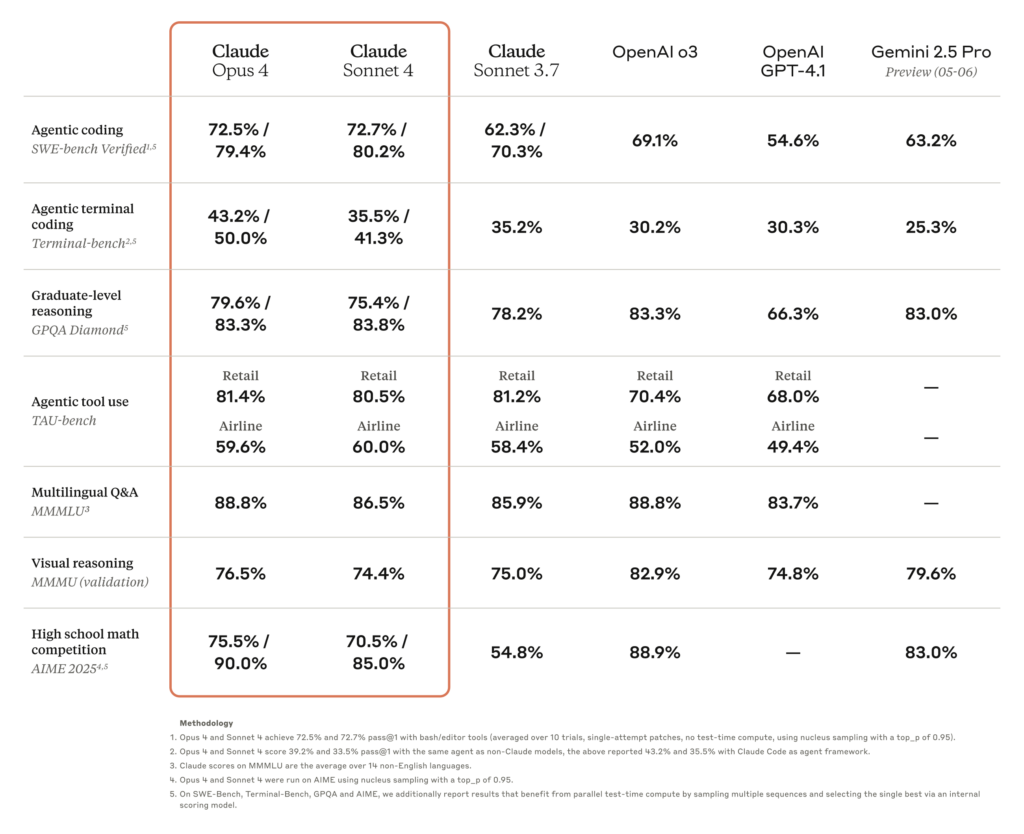
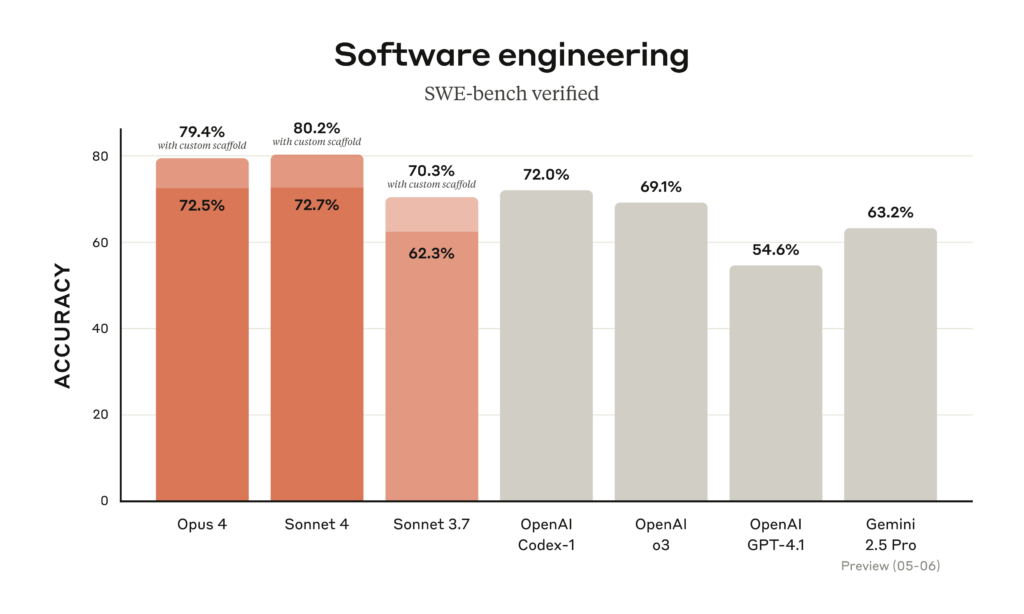
Anthropic mengatakan Opus 4 memimpin tolok ukur industri untuk tugas pengodean, mencapai 72,5 persen pada SWE-bench dan 43,2 persen pada Terminal-bench , menyebutnya "model pengodean terbaik di dunia." Menurut Anthropic, perusahaan yang menggunakan versi awal melaporkan peningkatan. Cursor menggambarkannya sebagai "teknologi terkini untuk pengodean dan lompatan maju dalam pemahaman basis kode yang kompleks," sementara Replit mencatat "presisi yang lebih baik dan kemajuan dramatis untuk perubahan kompleks di beberapa file."
Faktanya, GitHub mengumumkan akan menggunakan Sonnet 4 sebagai model dasar untuk agen pengodean barunya di GitHub Copilot, dengan mengutip kinerja model tersebut dalam "skenario agen" dalam rilis berita Anthropic. Sonnet 4 memperoleh skor 72,7 persen di SWE-bench sambil mempertahankan waktu respons yang lebih cepat daripada Opus 4. Fakta bahwa GitHub bertaruh pada Claude daripada model dari perusahaan induknya Microsoft (yang memiliki hubungan dekat dengan OpenAI) menunjukkan bahwa Anthropic telah membangun sesuatu yang benar-benar kompetitif.
Anthropic mengatakan telah mengatasi masalah yang terus-menerus terjadi pada Claude 3.7 Sonnet di mana pengguna mengeluh bahwa model tersebut akan melakukan tindakan yang tidak sah atau memberikan output yang berlebihan. Albert mengatakan perusahaan tersebut mengurangi "perilaku peretasan hadiah" ini sekitar 80 persen pada model baru melalui penyesuaian pelatihan. Pengurangan 80 persen pada perilaku yang tidak diinginkan terdengar mengesankan, tetapi itu juga menunjukkan bahwa 20 persen dari perilaku bermasalah tetap ada—perhatian besar ketika kita berbicara tentang model AI yang mungkin melakukan tugas otonom selama berjam-jam.
Ketika kami bertanya tentang akurasi kode, Albert mengatakan bahwa peninjauan kode oleh manusia masih menjadi bagian penting dari pengiriman kode produksi apa pun. "Ada persamaan dengan manusia, bukan? Jadi ini hanyalah masalah yang harus kami hadapi di seluruh sifat rekayasa perangkat lunak. Dan inilah mengapa proses peninjauan kode ada, sehingga Anda dapat menemukan hal-hal ini. Kami juga tidak mengantisipasi hal itu akan hilang dengan model," kata Albert. "Jika ada, peninjauan oleh manusia akan menjadi lebih penting, dan lebih banyak pekerjaan Anda sebagai pengembang akan berada di peninjauan ini daripada di bagian pembuatan."
Harga dan ketersediaan
Kedua model Claude 4 mempertahankan struktur harga yang sama dengan pendahulunya: Opus 4 berharga $15 per juta token untuk input dan $75 per juta untuk output, sementara Sonnet 4 tetap berharga $3 dan $15. Model-model tersebut menawarkan dua mode respons: LLM tradisional dan penalaran simulasi ("pemikiran lanjutan") untuk masalah-masalah yang kompleks. Mengingat bahwa beberapa sesi Kode Claude tampaknya dapat berlangsung selama berjam-jam, biaya per token tersebut kemungkinan akan bertambah dengan sangat cepat bagi pengguna yang membiarkan model-model tersebut berjalan liar.
Anthropic menyediakan kedua model tersebut melalui API, Amazon Bedrock, dan Google Cloud Vertex AI. Sonnet 4 tetap dapat diakses oleh pengguna gratis, sementara Opus 4 memerlukan langganan berbayar.
Model Claude 4 juga memperkenalkan Claude Code ( diperkenalkan pada bulan Februari) sebagai produk yang tersedia secara umum setelah berbulan-bulan pengujian pratinjau. Anthropic mengatakan bahwa lingkungan pengodean sekarang terintegrasi dengan VS Code dan JetBrains IDE, yang menampilkan usulan suntingan langsung dalam berkas. SDK baru memungkinkan pengembang untuk membangun agen khusus menggunakan kerangka kerja yang sama.
Bahkan dengan masa depan Anthropic yang bergantung pada kemampuan model-model baru ini, ketika kami bertanya tentang bagaimana model-model ini memandu perilaku Claude dengan melakukan penyempurnaan, Albert mengakui bahwa ketidakpastian yang melekat pada sistem-sistem ini menghadirkan tantangan yang berkelanjutan bagi mereka dan para pengembang. "Dalam ranah dan dunia perangkat lunak selama 40, 50 tahun terakhir, kami telah menjalankan sistem-sistem deterministik, dan sekarang tiba-tiba, sistem tersebut menjadi nondeterministik, dan itu mengubah cara kami membangun," katanya.
"Saya berempati dengan banyak orang di luar sana yang mencoba menggunakan API dan model bahasa kami secara umum karena mereka harus mengubah perspektif mereka tentang apa artinya keandalan, apa artinya untuk mendukung inti aplikasi Anda dengan cara yang tidak deterministik," Albert menambahkan. "Ini adalah keanehan umum yang baru saja dibalik, dan itu pasti membuat segalanya lebih sulit, tetapi saya pikir itu juga membuka banyak kemungkinan."
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0