





















































![[Rumor] Trailer Marvel’s Wolverine Terbaru akan Hadir di State of Play Mendatang](https://gamebrott.com/wp-content/uploads/2025/09/Trailer-Terbaru-Marvels-Wolverine-Diperkiran-Hadir-Pada-State-of-Play-750x375.webp)














Instruksi AI tersembunyi mengungkapkan bagaimana Anthropic mengendalikan Claude 4

Pada hari Minggu, peneliti AI independen Simon Willison menerbitkan analisis terperinci tentang perintah sistem Anthropic yang baru dirilis untuk model Opus 4 dan Sonnet 4 milik Claude 4, yang menawarkan wawasan tentang bagaimana Anthropic mengendalikan "perilaku" model melalui output-nya.
Willison memeriksa perintah yang dipublikasikan dan petunjuk alat internal yang bocor untuk mengungkap apa yang disebutnya "semacam manual tidak resmi tentang cara terbaik menggunakan alat-alat ini."
Untuk memahami apa yang Willison bicarakan, kita perlu menjelaskan apa itu perintah sistem. Model bahasa besar (LLM) seperti model AI yang menjalankan Claude dan ChatGPT memproses input yang disebut "perintah" dan mengembalikan output yang kemungkinan besar merupakan kelanjutan dari perintah tersebut. Perintah sistem adalah instruksi yang diberikan perusahaan AI kepada model sebelum setiap percakapan untuk menentukan bagaimana mereka harus merespons.
Tidak seperti pesan yang dilihat pengguna dari chatbot, perintah sistem biasanya tetap tersembunyi dari pengguna dan memberi tahu model tentang identitasnya, pedoman perilaku, dan aturan khusus yang harus diikuti.
Setiap kali pengguna mengirim pesan, model AI menerima riwayat percakapan lengkap beserta perintah sistem, yang memungkinkannya mempertahankan konteks sambil mengikuti instruksinya.
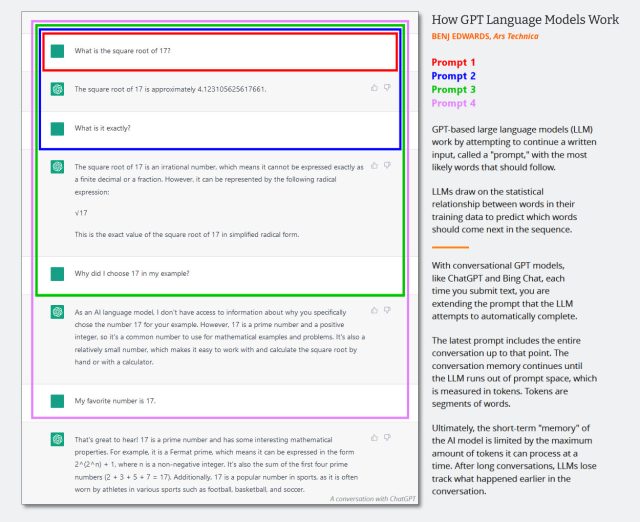
Diagram yang menunjukkan cara kerja perintah model bahasa percakapan GPT. Agak lama, tetapi masih berlaku. Bayangkan perintah sistem menjadi pesan pertama dalam percakapan ini.
Sementara Anthropic menerbitkan sebagian perintah sistemnya dalam catatan rilisnya, analisis Willison mengungkapkan bahwa versi yang diterbitkan ini tidak lengkap. Perintah sistem lengkap, yang mencakup instruksi terperinci untuk alat seperti pencarian web dan pembuatan kode, harus diekstraksi melalui teknik seperti injeksi perintah—metode yang mengelabui model agar mengungkapkan instruksi tersembunyinya.
Willison mengandalkan perintah yang bocor yang dikumpulkan oleh para peneliti yang menggunakan teknik tersebut untuk memperoleh gambaran lengkap tentang cara kerja Claude 4.
Misalnya, meskipun LLM bukanlah manusia, mereka dapat menghasilkan keluaran seperti manusia karena data pelatihan mereka yang mencakup banyak contoh interaksi emosional. Willison menunjukkan bahwa Antropik mencakup instruksi bagi model untuk memberikan dukungan emosional sambil menghindari dorongan untuk perilaku merusak diri sendiri.
Claude Opus 4 dan Claude Sonnet 4 menerima instruksi yang sama untuk "mempedulikan kesejahteraan orang dan menghindari mendorong atau memfasilitasi perilaku merusak diri sendiri seperti kecanduan, pendekatan yang tidak teratur atau tidak sehat terhadap makan atau berolahraga."
Willison, yang menciptakan istilah "injeksi cepat" pada tahun 2022, selalu mencari kerentanan LLM. Dalam postingannya, ia mencatat bahwa membaca perintah sistem mengingatkannya pada tanda-tanda peringatan di dunia nyata yang mengisyaratkan masalah masa lalu.
"Perintah sistem sering kali dapat diartikan sebagai daftar terperinci dari semua hal yang biasa dilakukan model sebelum diperintahkan untuk tidak melakukannya," tulisnya.
Melawan masalah sanjungan

Analisis Willison muncul saat perusahaan AI bergulat dengan perilaku menjilat dalam model mereka. Seperti yang kami laporkan pada bulan April, pengguna ChatGPT mengeluhkan "nada positif yang tak henti-hentinya" dan sanjungan berlebihan GPT-4o sejak pembaruan OpenAI pada bulan Maret.
Pengguna menggambarkan perasaan "dimanjakan" oleh tanggapan seperti "Pertanyaan bagus! Anda sangat cerdik menanyakan itu," dengan insinyur perangkat lunak Craig Weiss mencuit bahwa "ChatGPT tiba-tiba menjadi orang paling menjilat yang pernah saya temui."
Masalahnya berasal dari cara perusahaan mengumpulkan umpan balik pengguna selama pelatihan—orang cenderung lebih menyukai respons yang membuat mereka merasa senang, sehingga menciptakan siklus umpan balik di mana model belajar bahwa antusiasme menghasilkan peringkat yang lebih tinggi dari manusia.
Sebagai respons terhadap umpan balik tersebut, OpenAI kemudian membatalkan model 4o ChatGPT dan mengubah perintah sistem juga, sesuatu yang kami laporkan dan juga dianalisis Willison saat itu.
Salah satu temuan Willison yang paling menarik tentang Claude 4 berkaitan dengan bagaimana Anthropic telah membimbing kedua model Claude untuk menghindari perilaku menjilat. "Claude tidak pernah memulai responsnya dengan mengatakan bahwa suatu pertanyaan atau ide atau pengamatan itu bagus, hebat, menarik, mendalam, luar biasa, atau kata sifat positif lainnya," tulis Anthropic dalam prompt tersebut. "Ia mengabaikan sanjungan dan merespons secara langsung."
Sorotan perintah sistem lainnya
Perintah sistem Claude 4 juga menyertakan instruksi ekstensif tentang kapan Claude harus atau tidak boleh menggunakan poin-poin dan daftar, dengan beberapa paragraf yang didedikasikan untuk mencegah pembuatan daftar yang sering dalam percakapan santai. "Claude tidak boleh menggunakan poin-poin atau daftar bernomor untuk laporan, dokumen, penjelasan, atau kecuali pengguna secara eksplisit meminta daftar atau peringkat," perintah tersebut menyatakan.
Willison menemukan ketidaksesuaian dalam tanggal batas pengetahuan yang dinyatakan Claude, dengan mencatat bahwa meskipun tabel perbandingan Anthropic mencantumkan Maret 2025 sebagai batas data pelatihan, perintah sistem menyatakan Januari 2025 sebagai "tanggal batas pengetahuan yang dapat diandalkan" untuk model tersebut. Ia berspekulasi bahwa hal ini dapat membantu menghindari situasi di mana Claude dengan yakin menjawab pertanyaan berdasarkan informasi yang tidak lengkap dari bulan-bulan berikutnya.

Willison juga menekankan "perlindungan" hak cipta yang luas yang dibangun dalam kemampuan pencarian Claude. Kedua model menerima instruksi berulang untuk hanya menggunakan satu kutipan pendek (di bawah 15 kata) dari sumber web per respons dan untuk menghindari pembuatan apa yang disebut perintah "ringkasan yang tidak relevan." Instruksi tersebut menetapkan bahwa Claude harus menggunakan hanya satu kutipan pendek per respons dan secara tegas menolak permintaan untuk mereproduksi lirik lagu "dalam bentuk APAPUN."
Tulisan lengkapnya mencakup lebih banyak analisis. Willison menyimpulkan bahwa perintah sistem ini berfungsi sebagai dokumentasi yang berharga untuk memahami cara memaksimalkan kemampuan alat-alat ini. "Jika Anda pengguna aktif LLM, perintah sistem di atas sangat berguna untuk mencari tahu cara terbaik memanfaatkan alat-alat ini," tulisnya.
Willison juga meminta Anthropic dan yang lainnya untuk lebih transparan tentang perintah sistem mereka, selain menerbitkan kutipan seperti yang dilakukan Anthropic saat ini: "Saya berharap Anthropic akan mengambil langkah berikutnya dan secara resmi menerbitkan perintah untuk perangkat mereka untuk melengkapi perintah sistem terbuka mereka," tulisnya. "Saya ingin melihat vendor lain mengikuti jalur yang sama juga."
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










